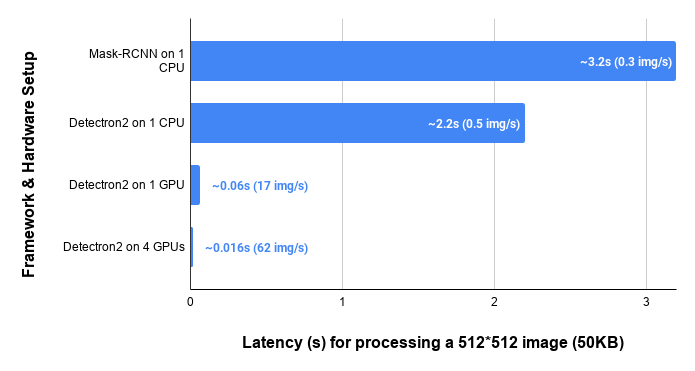
Setup Specifications
We did not have access to a real robot because of the COVID-19 pandemic, so all the implementations and experiments are carried out in a simulated environment in CoppeliaSim. The simulator provides a mature physics engine which simulates gravity and friction in a realistic manner.
We used Rethink Robotics Sawyer, a 7-DOF robot.
We used RelaxedIK, a motion planning platform, to calculate the motion of the robot arm. RelaxedIK maps a 6-DOF pose goal (position + rotation) to a robot configuration in a fast and accurate way.
The CPU we used for the experiments is an AMD Ryzen 7 2700X Eight-Core Processor 3.70GHz, and we did not have access to a GPU.
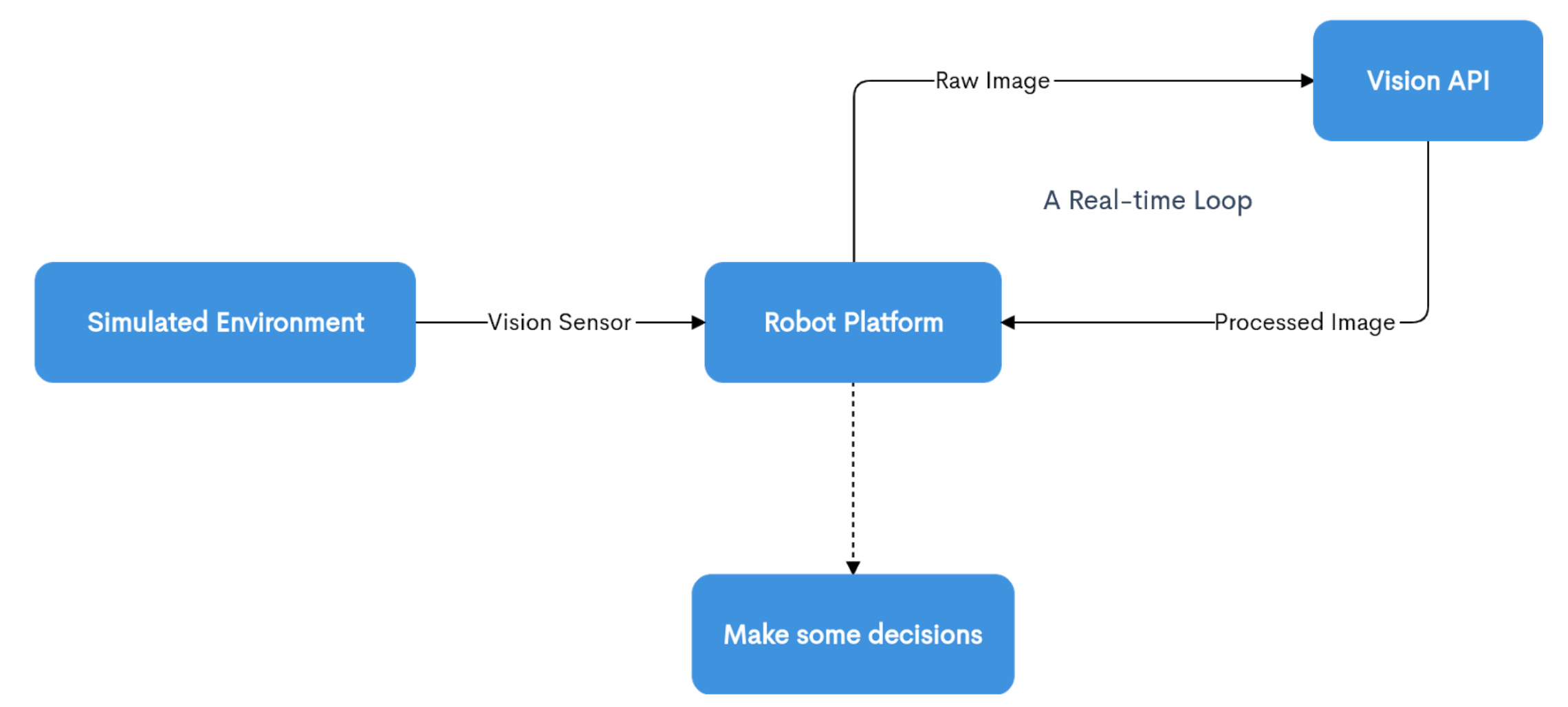
An overview of the pipeline