Taking a panorama
A real robot is not accessible to us due to the Covid-19 pandemic, so we decided to carry out our implementation and experiments in a simulated environment as shown in Fig. 1. For this task, we tested a Rethink Robotics Sawyer (7-DOF) in a scene simulated in CoppeliaSim [1].
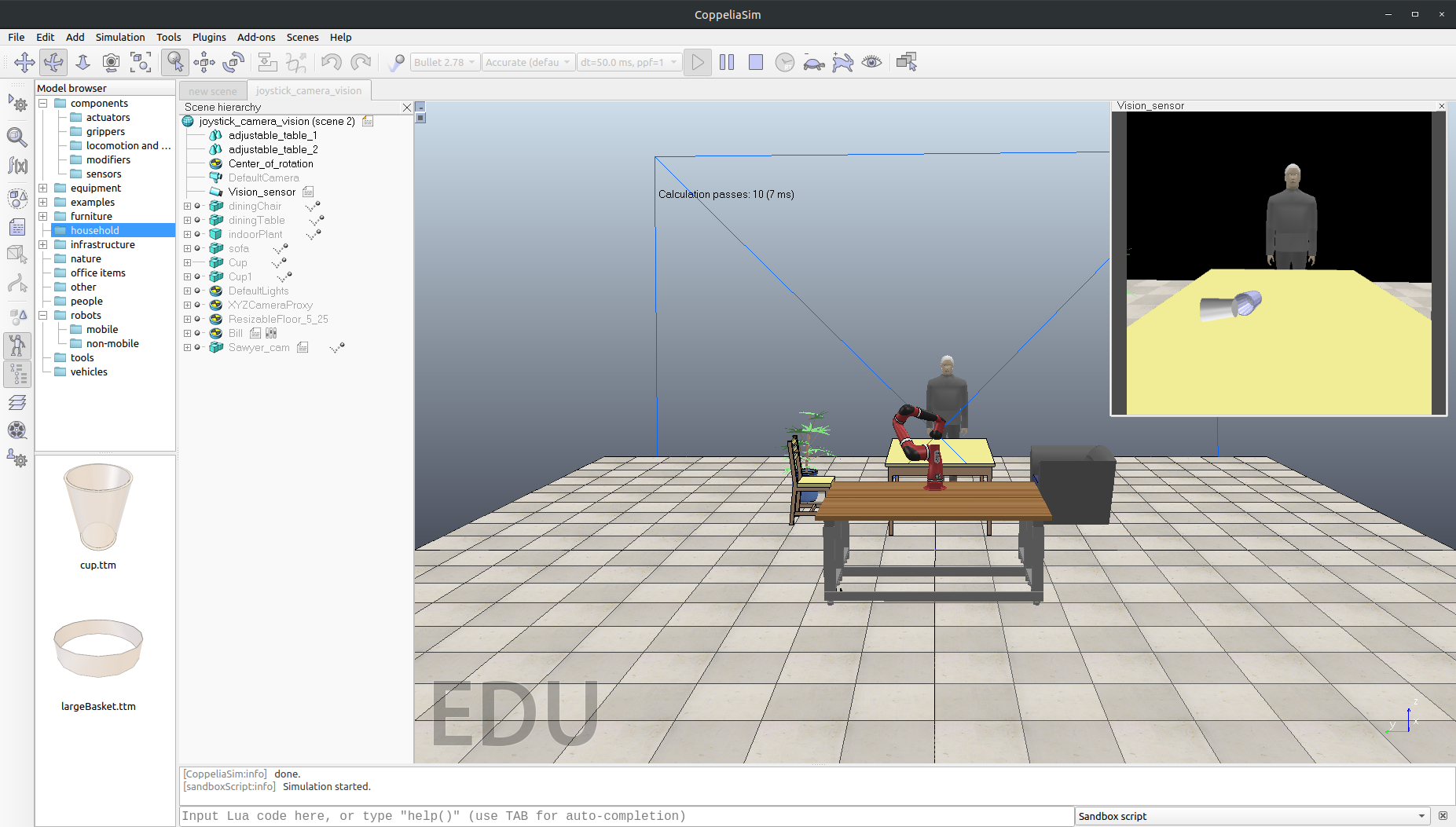
Fig. 1. A screenshot of the simulated scene in CoppeliaSim
We used two control methods to test our implementation: (1) A user uses an Xbox game controller (also known as a joypad) to interactively drive the Sawyer robot. (2) Make the Sawyer robot automatically follow a motion path in the cartesian space.
In both methods, we controlled the Sawyer robot to rotate 150 degrees around its wrist (link 7) at a fixed position. During the rotation, we used the camera attached to the end effector of the Sawyer robot to capture images with an interval of 0.3s. After we obtained the images, we combined them into a panorama with the OpenCV stitcher [7]. The images before and after stitching are shown in Fig. 2 and 3.

Fig. 2. Images captured by the camera robot

Fig. 3. The panorama after stitching
We also did a very simple user study with a sample size of 3. In this study, each user had some knowledge about how to use a game controller but no prior experience of manipulating a robot. We asked them to control the Sawyer robot to take a panorama using our method (1). We didn't provide any instructions (such as how to use each button on the game controller) for them in order to test how intuitive our interactive control method is. It takes them about 5 minutes on average to complete the task, and our method is considered relatively easy to use based on their feedback.

